P3183 - Accuracy of a Popular Online Chat-Based Artificial Intelligence Model in Providing Recommendations on Colorectal Cancer Screening and Polyps: A Patient vs Physician-Centered Approach
Joseph Kassab, MD1, Carol A. Burke, MD, FACG1, Carole Macaron, MD2, Joseph El Dahdah, MD2, Anthony Kerbage, MD2, Michel Chedid El Helou, MD1, Carol Rouphael, MD2 1Cleveland Clinic Foundation, Cleveland, OH; 2Cleveland Clinic, Cleveland, OH
Introduction: The rise in online chat-based artificial intelligence (AI) interactions raises the question of whether AI can assist in patient education and provide guidelines-based recommendations for physician use. We investigated if ChatGPT 4.0, a popular AI chatbot, could accurately answer patient queries and provide recommendations to physicians on colonoscopy and colorectal cancer (CRC) screening.
Methods: We created 2 sets of 15 questions each, one from a patient (PA) and another from a physician’s (PH) perspective. PA questions were formulated after querying “Google Trends” for most searched terms related to colorectal polyps and colonoscopy. PH questions were formulated by expert gastroenterologists. Questions were entered into ChatGPT on 5/10/2023 and the model was asked to provide references to answers. 3 gastroenterologists reviewed answers and references and graded them for accuracy. An answer was considered accurate when appropriate with complete information and inaccurate if information was inaccurate or essential information missing. References were graded as suitable, unsuitable (existent but unrelated to answer) or nonexistent (created by ChatGPT). If >1 reference per answer, the overall grade represented the incorrect reference. Free-marginal Fleiss kappa coefficients (κ) were generated to determine agreement level among reviewers. Answers with disagreement were discussed by all 3 gastroenterologists with a chance to modify the grade after discussion.
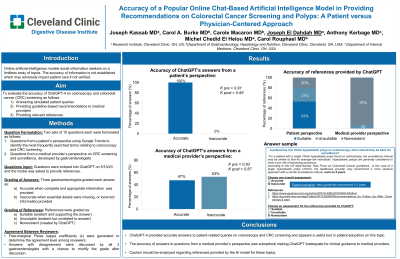
Results: When looking at accuracy of answers generated, κ among reviewers was 0.83 (95% confidence interval CI 0.35, 0.95) for PH and 0.91 (95% CI 0.58, 1.00) for PA answers, indicating almost perfect agreement (APA). The discrepancies in grading were identified and discussed. Subsequently, 100% of PA answers were graded as accurate (κ = 0.95 (95% CI 0.74, 1.00), APA) and 47% of PH answers graded as accurate (κ = 0.87 (95% CI 0.45, 1.00), APA) (p< 0.00001 by Fisher’s exact test comparing PA vs PH accuracy level) (Table). 53% of PA references were suitable, 27% unsuitable and 20% nonexistent. 93% of PH references had at least one nonexistent reference and one was unsuitable.
Discussion: ChatGPT provided largely accurate answers to PA questions on colonoscopy and CRC screening, indicating it could be a useful tool in patient education on CRC screening. The accuracy of answers to PH questions was suboptimal and should not be used by physicians for clinical guidance. Caution should be employed with references provided by the AI model.
Disclosures:
Joseph Kassab indicated no relevant financial relationships.
Carole Macaron: EMTORA BIOSCIENCES – COINVESTIGATOR ON A RESEARCH STUDY SUPPORTED BY EMTORA.
Joseph El Dahdah indicated no relevant financial relationships.
Anthony Kerbage indicated no relevant financial relationships.
Michel Chedid El Helou indicated no relevant financial relationships.
Carol Rouphael indicated no relevant financial relationships.
Joseph Kassab, MD1, Carol A. Burke, MD, FACG1, Carole Macaron, MD2, Joseph El Dahdah, MD2, Anthony Kerbage, MD2, Michel Chedid El Helou, MD1, Carol Rouphael, MD2. P3183 - Accuracy of a Popular Online Chat-Based Artificial Intelligence Model in Providing Recommendations on Colorectal Cancer Screening and Polyps: A Patient vs Physician-Centered Approach, ACG 2023 Annual Scientific Meeting Abstracts. Vancouver, BC, Canada: American College of Gastroenterology.